Wenn wir von Zero Trust Network Architecture oder Access (ZTNA) sprechen, dann wird allzu oft dies auf ein Produkt heruntergebrochen. Damit wird das Thema jedoch auf ein Produkt reduziert, was dem ZTNA Ansatz so nicht ganz gerecht wird.
Denn ZTNA ist kein einzelnes Produkt, sondern eine Architektur oder gar eine eigene Philosophie. Im Grunde genommen beschreibt ZTNA den Vorgang eines Zugriffs, wobei wir jede Interaktion als nicht vertrauenswürdig (Zero Trust) betrachten. Da ein einzelner Client heute nicht mehr für sich arbeiten kann und es dem User schlicht weg keinen Spass machen würde nur für sich zu sein, sei dies ein interner Server oder ein Server im Internet (Network). Diesen Zugriff müssen wir betrachten, bewerten und schliesslich durch eine Action entsprechend steuern (Access).
Zscaler Inc. hat hierzu ein sehr gutes Grundkonzept. Dieses beinhaltet sieben Elemente kategorisiert in die drei Schichten “Verifikation”, “Control” und “Enforce”. Auf diese ich im Nachfolgenden vertieft drauf eingehen möchte.
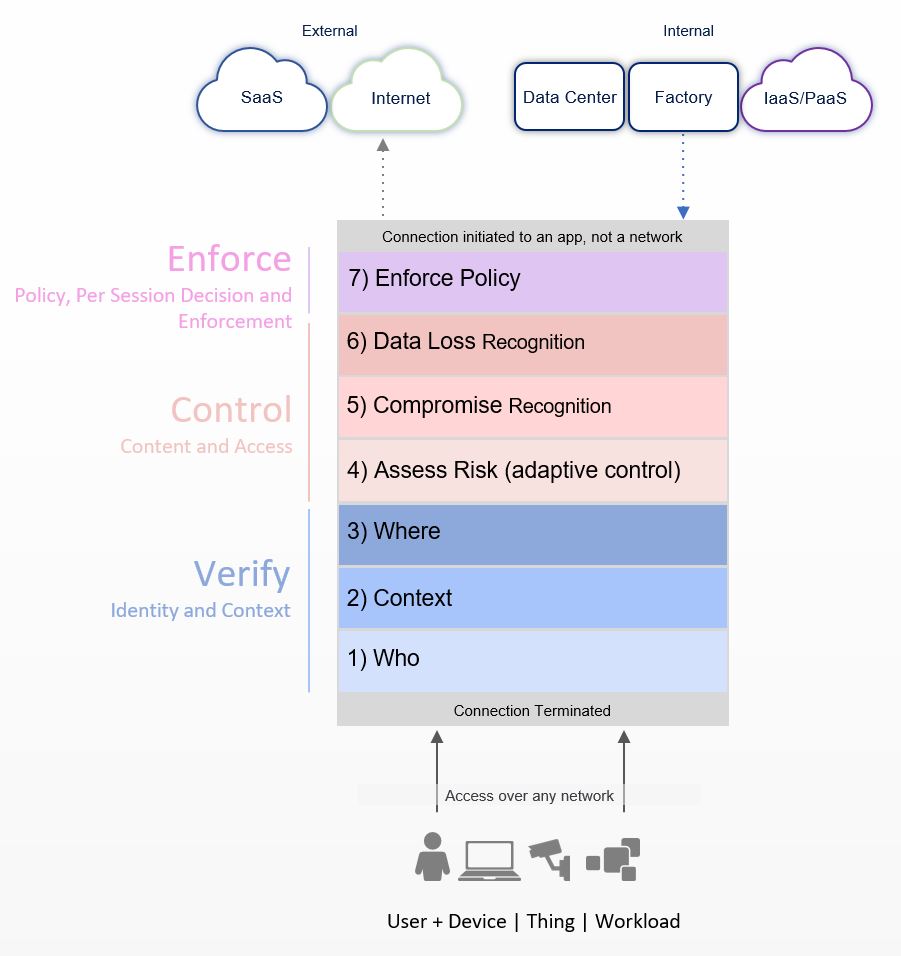
Die sieben Elemente in drei Schichten
1. Schicht – Verifikation
Hier geht es in drei Schritten (Who, Context, Where) darum, dass wir verstehen, wer oder was den Zugriff versucht und wohin diese Access stattfindet.
Who
Das klingt im ersten Moment recht simpel, birgt dennoch einige Herausforderungen. “Who” oder «Wer» kann bedeuten, dass ein User einen Access verursacht. Dazu benötigen wir ggf. noch weitere Details wie den Usernamen, welcher Usergruppe der User oder welchem Department dieser angehört usw. um damit später granularere Regeln bauen zu können. Dies können wir durch Anbindung an eine andere Datenquelle ermitteln – zum Beispiel durch den Einsatz von SAML, bei welchem wir Userdaten aus unserem Active Directory herauslesen.
“Who” kann auch bedeuten, dass ein Server (“Workload” bezeichnet) einen Zugriff versucht. Hierbei können wir dann unterteilen aus welchem Netz oder welcher Gruppe dieser angehört, indem wir entsprechende Gruppierungen oder Schemata hinterlegen. Gleiches kann bedeuten, wenn es sich beim “Who” um ein IoT Gerät wie einem Drucker, Scanner oder Messfühler handelt.
Context
Im nächsten Schritt ist es wichtig zu verstehen, was der Kontext des Zugriffes ist. Wir müssen also verstehen:
Woher kommt der Zugriff? Ist der Zugriff in einer bestimmten Lokation oder kommt dieser Zugriff als Road Warrior aus dem Internet? In welche Richtung geht der Zugriff (z.B. Up- oder Download, Get oder Push)? Handelt sich es sich bei dem Zugriff um ein vertrauenswürdiges Gerät (durch Verwendung gewisse Endpoint Checks)?
Den Kontext zu verstehen ist essentiell, denn ein Zugriff eines Servers oder IoT Geräts aus einer nicht bekannten Location gilt es anders einzustufen, als einen User der von einem Firmengerät zugreift.
Es geht auch darum Anomalien zu detektieren. So kann es zum Beispiel nicht sein, dass ein User innerhalb kürzester Zeit (z.B. wenige Stunden) einen Zugriff aus Europa und wenig später aus Amerika durchführen kann. Gegebenenfalls aus dem Kontext kann abgeleitet werden, ob der User sich nochmals mittels zweiten Faktors authentifizieren muss.
Where
Im letzten Schritt dieser Schicht gilt es zu verstehen «where» oder «wohin «der Zugriff stattfindet – daher was die Destination ist.
Ist es ein interner Server? Ein SaaS Applikation? Ein Zugriff ins Internet? Eine Workload in unserem Datacenter? etc.
2. Schicht – Control
Nachdem wir nun verstanden haben, wer in welchem Kontext wohin zugreifen möchte gilt es in dieser Schicht zu verstehen, welches Risiko besteht.
Access Risk Recognition
Als erstes versuchen wir bei dieser Schicht zu verstehen, welches Risiko besteht und was die potenziellen Auswirkungen sein könnten. Dies könnte z.B. der Schutz von Malware sein, das Erkennen von Phising-Attacken, die Verwendung von bestimmter Applikation oder Verwundbarkeit oder Attacken und den Vektor entsprechend zu klassifizieren.
Compromise Recognition
Als nächstes geht es darum, eine Kompromittierung zu erkennen. Dabei können wir mittels Patterns oder Signaturen bestimmte bekannte Gefahren erkennen oder unbekannte Gefahrendurch Analyse und Sandboxing entsprechend versuchen zu detektieren. Dies kann bei Daten im Transit inline oder, wenn die Daten ruhen, via API (z.B. out-of-band CASB) passieren.
Die Anbindung an mehrere Datenquellen durch Kooperationen über Threat Feeds oder das Sharing der gelernten Informationen sind ein essentieller Faktor, der sowohl die Security als auch die Experience erhöht.
Data Loss Recognition
Ebenfalls in dieser Schicht spielt nicht nur der Schutz durch Gefahren eine Rolle, sondern auch der Verlust von klassifizierten Daten. Sei dies durch generell bekannte Patterns (Exact Data Match – z.B. Kreditkarten Nummern), durch persönliche Patterns (Index Data Matching – Customer Data Set), individuelle Klassifizierungen der Daten (z.B. mittel Microsofts Azure Information Protection [AIP]) oder simplen erkennen und blockieren von File-Typen.
Hier sollte der File-Typ nicht nur anhand der File-Endung erkannt werden sondern ebenfalls eine OCR Erkennungen stattfinden um die Data Loss Erkennung zu erhöhen.
Bei allen drei Elementen dieser Schicht kommen verschiedene Schnittstellen, Datenbanken und Technologien am besten zum Einsatz: AV-Scanner oder ATP-Lösungen, Verhaltenserkennungen wie Sandboxing und Anomalie Erkennung, Anbindung von APIs oder Newsfeed (z.B. CVE Databases oder Theat Feeds), sowie auch Datenklassifizierungen sind hier nur einige Stichpunkte die ich als Beispiel anführen möchte.
3. Schicht – Enforcement
In allen Schichten bisher haben wir nun verstanden, wer oder was einen Zugriff erzeugt und was passiert. Wir haben nun im besten Fall das Risiko und die Tragweite erkannt oder wissen optimalerweise exakt was passieren wird oder ob es sich um eine unbekannte Aktion mit unbekanntem Risiko handelt. Nun müssen wir letztlich noch definieren was die daraus resultierende Aktion ist – doch welche ist das nun?
Jetzt kommt Ihnen sicherlich als erstes in den Sinn, dass man dieses simple Erlauben oder Blockieren kann. Es gibt jedoch noch einige Aktionen die vielleicht ebenfalls in Betracht kommen oder verschachtelt miteinander werden können. Ich werde diese einfach mal in die Kategorien «Conventional», «Conditianal Allow» und «Conditianal Block» definieren.
Wichtig hierbei ist, dass wir jede Policy per Session und per Zugriff geprüft und bewertet und nicht global eine Annahme getroffen wird.
Conventional
- Allow: Bei der Aktion erlauben wir den Zugriff.
- Block: Bei der Aktion verbieten wir den Zugriff.
Conditianal Allow
- Warn: Bei dieser Aktion warnen wir den Nutzer vor einem Risiko, geben diesen die Möglichkeit weiter fortzufahren.
- Prioritize / Deprioritize: Entsprechend können wir den Access priorisieren. So können wir Business Kritischen Anwendungen erhöhte Ressourcen zuteilen.
- Steer: Neben Prioritäten können wir auch vorgegebene Pfade definieren auf welchen der Zugriff stattfinden kann (z.B. IP Source Anchoring)
- Isolate: Die Cloud Browser Isolation ist hier zu nennen, dabei wird die entsprechende Destination (z.B. eine Webseite) in der Cloud in einem Container ausgeführt und lediglich ein Pixel-Stream an den Client übermittelt. Schadware bleibt so in dem Container und wir beim Beenden entsprechend gelöscht.
- Quarantine: hier wird der Zugriff limitiert erlaubt, jedoch geschützt (z.B. WAF)
Conditianal Block
- Quarantine: hier wird der Zugriff verboten aber bewertet.
- Deceive: Hier wird der Zugriff auf eine separate vorgetäuschte Umgebung (engl. deceive) umgeleitet – oft auch als Honeypot bezeichnet – und das Verhalten dort zu generell ausführen zu lassen und zu analysieren.
Zero Trust Exchange – mit den Workloads verbinden
Abschliessend nachdem eine Aktion definiert wurde, muss unseres Zero Trust Exchange mit der entsprechenden Workload oder Applikation verbunden werden.
Externe Workloads
Dabei wird, wenn sich die Workloads im Internet oder in einer SaaS befindet, eine neue Verbindung im Namen des «who» (User, Server, IoT) aufgebaut – der Zero Trust Exchange agiert hier als Proxy. Dabei bleibt der einzelne User aus Sicht der Applikation anonym, was einen zusätzlichen Schutz vor «watering hole attacks» – eine Sicherheitslücke durch analysieren des Verhaltens, bei der der Angreifer versucht, eine bestimmte Gruppe von Endbenutzern zu kompromittieren, indem er Websites infiziert – gibt.
Interne Workloads
Bei intern Workloads (z.B. im Datacenter, IaaS oder PaaS) werden diese Apps als einzelne Ziele betrachtet und nicht als Netzwerke (DMZ oder SaaS), was zudem den Schutz vor «lateral threat movement» begünstigt. Darüber hinaus sind diese für den Client generell unsichtbar und speziell für nicht authentifizierten Zugriff nicht detektierbar. Das Prinzip des inside-out Verbindungsaufbau (wie z.B. bei ZPA) sorgt generell dafür, dass es keine eingehenden Verbindungen gibt und wir so von extern nicht angreifbar sind. Letztlich schützen wir Workloads auch dadurch, dass wir diese nicht durch Netzwerksegmente separieren, sondern als einzelne Apps betrachten und mittels des Zero Trust Exchange in Hinblick auf den Zugriff eine Microsegmentierung erreichen.
Microsegmentation – der letzte Schritt im ZTNA
Offen bleibt letztlich nur noch die Workload to Workload Segmentierung (reine Microsegmentierung auf Netzwerk oder gar Service Ebene) welche ebenfalls ein weiterer Baustein des Zero Trust Network Access bildet und ich an dieser Stelle noch nicht betrachtet habe…